Benchmarks
We benchmark what we ship
Our benchmarks are designed to be checked:
- We benchmark what we ship. Every eval runs against a pinned, publicly downloadable Ante release, the same binary
ante updateinstalls (e.g.0.preview.43). No eval-only branches, no benchmark-specific prompts. - The runs are auditable. Every result links its raw Harbor run, so anyone can inspect the trials behind the number.
- The constraints are official. All trials use the same parameters as the official Terminal-Bench leaderboard: 89 tasks, 5 trials per task, strict timeouts and hardware limits.
- The results are live. We publish continuously at antigma.ai/eval.
Terminal-Bench 2.1: one harness, any model
We evaluate the agent harness, not the model. So instead of one hero number, we publish Ante's score across many models. For every model we run, Ante is the #1 same-model agent: no other harness posts a higher score with that model.
Highlights from the live dashboard (as of June 2026):
| Model | Accuracy | Same-model rank |
|---|---|---|
| GLM 5.2 | 74.6% ±2.06 | #1 |
| MiMo V2.5 | 65.8% ±2.30 | #1 |
| DeepSeek V4 Pro | 65.8% ±2.25 | #1 |
| DeepSeek V4 Flash | 62.7% ±2.29 | #1 |
| MiniMax M3 | 62.1% ±2.33 | #1 |
Two things worth noticing:
- Ante + GLM 5.2 at 74.6% would place in the top 7 of the public verified leaderboard, with an open-weight model.
- Ante + DeepSeek V4 Pro reaches 65.8%: comparable accuracy to frontier closed-model harness combinations on the public leaderboard, for about $36 of inference across the full 445-trial run.
A good harness moves the frontier down-market: it makes open-weight models do work you'd otherwise pay frontier prices for.
Track record
- #1 on the Terminal Bench 1.0 leaderboard (2025)
- #1 on the Terminal Bench 2.0 leaderboard among verified agents — and best in class among Gemini-based agents (February 2026)
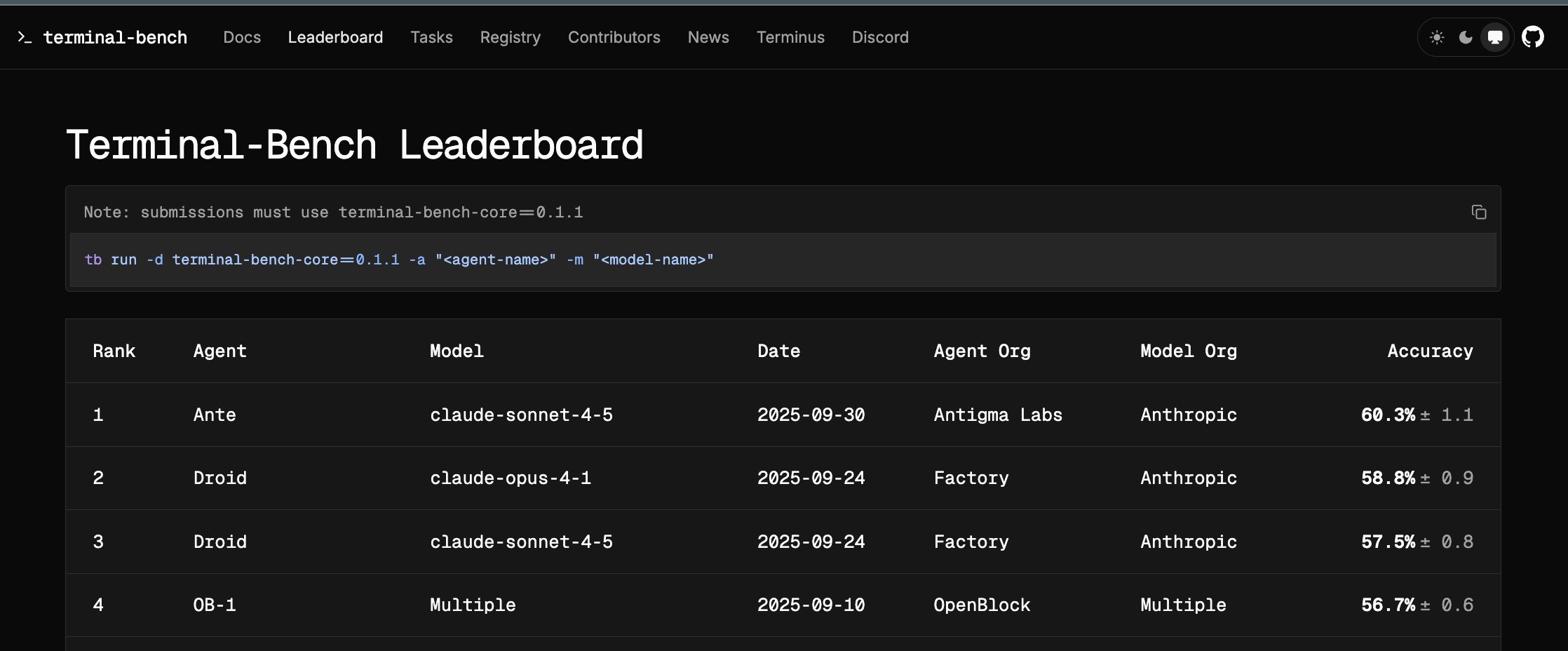
Terminal Bench 1.0. Ante placed first on the public leaderboard on September 30, 2025.
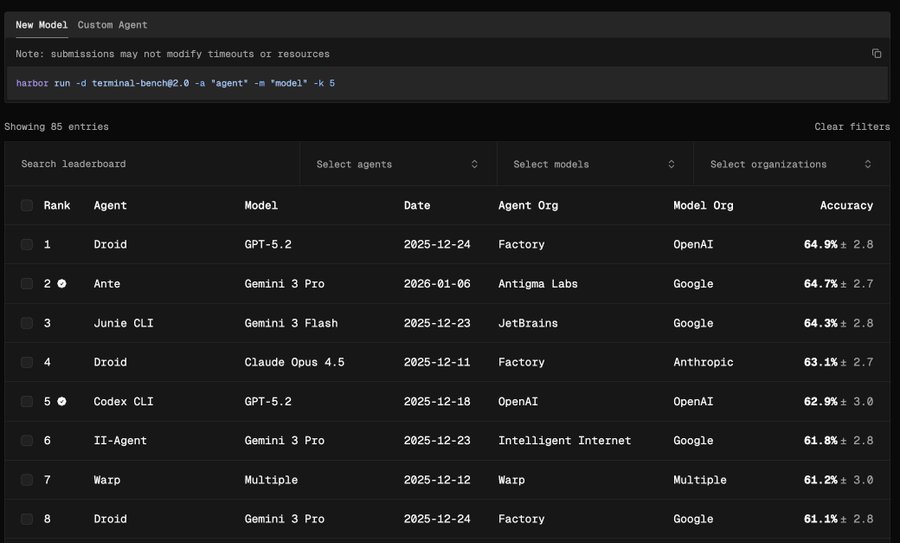
Terminal Bench 2.0. Ante ranked #1 among verified agents on January 6, 2026 — 2nd overall, and the highest-ranked Gemini-based agent in the displayed leaderboard.
We use Terminal Bench and Harbor as our primary external benchmark. The team behind Harbor and Terminal Bench are genuine researchers — rigorous, principled, and motivated by getting it right rather than hype.
Why Terminal Bench:
- Rigorous. Unambiguous task specs, deterministic grading where possible, and isolated execution environments.
- Focused on core capability. Can the agent accomplish real tasks in a real shell? Reading context, reasoning, acting, verifying — the exact loop we are building Ante around.
Resource footprint
Capability is half the story; cost to run is the other half. See Resource Footprint for Docker-measured CPU, memory, and disk usage across 20 parallel tasks — Ante vs Claude Code vs Opencode.
Evaluation principles
Most of the magic comes from the model — but the agent harness is the critical conduit between human and AI.
We evaluate the agent and how well it channels the model's power — not the model itself.
Improve the harness, not the prompt. When eval scores need to go up, we invest in the agent chassis — the runtime, orchestration, reliability — not in prompt-engineering for a specific benchmark. If a score improves because the system genuinely got better, it stays improved. If it improved because we tuned a prompt, it's fragile. Start early, start simple. A small but honest eval set drawn from actual failures beats a large contrived one. Isolate and reproduce. Every eval run starts clean. When a score drops, we know it reflects a real regression.